Overview
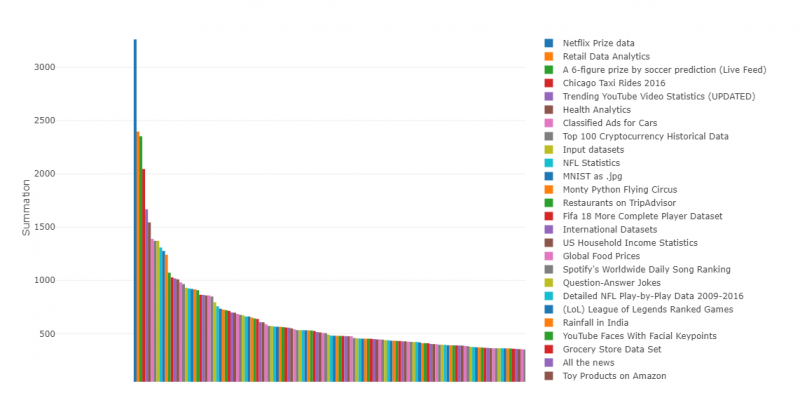
In this 5 Minute Analysis we are exploring a Kaggle dataset about Kaggle datasets. This dataset lets us see a list of the datasets on Kaggle, and shows which ones have the most engagement and activity. Our goal is to explore and filter the data to find popular datasets with many downloads but very few kernels. As a contributor to Kaggle, you may want to add kernels to datasets that fit this criteria as opposed to datasets with lots of kernels where your submission might get lost among the crowd.
Steps
Unlike in past posts, instead of listing the steps, we have simply included a video that shows the whole process from start to finish. This includes downloading the data files, uploading to Pivot Billions, filtering the data and then creating the pivot table. The filters we used were kernel counts less than 5 and download counts greater than 100. We timed the process and the whole thing takes slightly more than 3 minutes from start to finish.
The Wrap-up
From the pivot table we can immediately see a variety of very popular datasets that have been downloaded thousands of times yet have very few or no kernels developed.
Many of these are likely underutilized datasets that may not be easily understood using existing tools and could benefit from additional exploration and analysis incorporating new tools such as PivotBillions.